Some of the things we hate to spend time while development are setting up environments, building and deploying stuff. But good news is nowadays there are plenty of tools to solve this. In this post I would like to share a very quick way of becoming a DevOps overnight and automating all the boring part of getting your product running seamlessly as you develop.
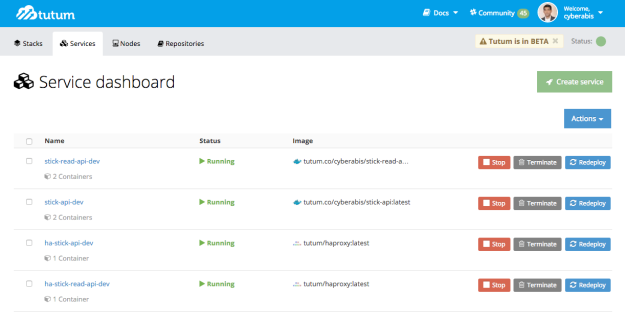
Snapshot of my Tutum Services after setting up continuous deployment
#1. Iaas, Paas, Saas and tech stack decisions
At the start of our project we had to decide how our tech stack is going to be – our philosophy was to use Iaas for any stateless process or jobs like API servers or event processors. For persistence alone we decided to go with Saas solutions. We picked up NodeJS for APIs and Java / Python for daemon processes. Being part of Microsoft Bizspark, we run all these processes on Azure Linux instances. For temporary persistence, we found AWS pretty good performance or price wise and picked up Kinesis + DynamoDB. S3 was chosen for long term storage. The strategy was to be able to easily swap across cloud service providers at any point in future with almost no tight coupling with any vendor.
#2. Local development
Local development has to be as fast as possible – personally I find using docker in my early stages of development slows me down and also messes up my local machine with chunky images. So on my local machine I prefer to stick to run my apps in the standard way without any containerization.
#3. Dockerization
Docker is simply awesome when it comes to deploying programs to cloud instances. I can also easily horizontal scale test, load balance test with just multiple docker container instances on a single node. All that’s needed is to add a simple Dockerfile in every project directory. A NodeJS example is shown below.
FROM node:0.12
# Bundle app source
ADD . /src
# Install app dependencies
RUN cd /src; npm install
EXPOSE 3000
CMD ["node", "/src/app.js"]
#4. Continuous deployment with Tutum
Tutum is still in Beta, but it’s awesome and free (atleast for now)! The first step in setting up Tutum is to go to Account Info and add Cloud Providers and Source Providers – in our case it’s Microsoft Azure and GitHub. Tutum has a very clear definition of the components required for setting up a continuous deployment:
a. Repository – Here we create a new (private) repository in Tutum and link to our GitHub to sync on every update. The source code gets pulled from GitHub and docker images are built inside Tutum’s repository with every GitHub update.
b. Node – We can create Azure instances right from Tutum. You have to set up Tutum to be able to get access to Azure. Each instance is a Node in Tutum.
c. Services – A service is a process or a program that you run. Services can comprise of one or more docker containers depending upon if we scale or not. Services can be deployed on one or more nodes to horizontally scale.
While creating Nodes and Services, Tutum allows to specify tags like “dev”, “prod”, “front-end”, “back-end”. The tags determine on what nodes a service gets deployed. Thus we can have separate nodes for “front-end dev”, another for “font-end prod” etc.
Tutum is not super fast yet – I believe it’s mainly due to the time taken to build docker images. But still decent enough. For continuous deployment, we have to specify “Autodeploy” option while creating the service. Another good feature I found with Tutum is that there are jumpstart services like HA load balancer – it really makes setting up a high availability API cluster a breeze.
#5. Slack Integration
Like so many other startups we are quite excited about Slack. I have seen Slack integration with other Continuous Integration products like Circle CI and was surprised to see even Tutum Beta had that. I created a new channel in our Slack and from Integration settings enabled Incoming Webook – this gives an URL I have to paste in Tutum > Account Info > Notifications > Slack. And that’s it, we have a continuous deployment ready with all the bells and whistles.
Like I mentioned at the start there are multiple options to automate build, test and deployment. This post suggests a very economic yet scalable solution using Tutum – and literally I was able to learn and get everything running overnight!


